When it comes to big data, there are two main categories: batch and streaming. Batch handles all your data at once while streaming looks at the data the moment it arrives. This data is often multivariate, described by several features.
What is iForestASD?
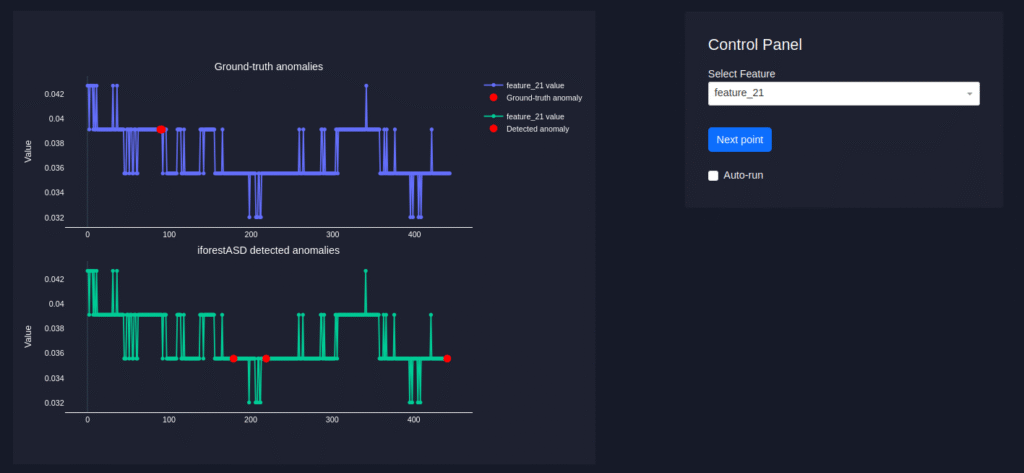
iForestASD (iForest for Anomaly Detection in streaming data) is an extension of the classical Isolation Forest, designed for data streams.
Intuition behind iForest
iForest is based on a simple idea: anomalies are rare and different, therefore they are easier to separate from normal points. A point is an outlier if it can be isolated with a small number of splits.
Streaming workflow
- Streaming data is processed using a fixed-size sliding window that contains the most recent data points and represents the current system state.
- Apply iForest detector on the window.
-
For each incoming point, an anomaly score is computed based on the average path length.
Shorter average path length → higher anomaly probability
Handling Concept Drift (conditional update)
- After processing a sliding window, compute the anomaly rate.
- Compare the anomaly rate with a predefined anomaly rate u.
- If anomaly rate < u: the model remains valid, no update is needed.
- If anomaly rate ≥ u: a concept drift is assumed, the current model is discarded, and a new iForest Detector model is trained on the current window.
Implementation
The implementation can be found in the following repository, which demonstrates the use of iForestASD with the PSM dataset using the pysad library: https://github.com/Emaha-Clems/iforestASD .